Turn that code upside down :)
Abstraction, I/O, subroutines, and how to use them well
(Almost) all example code written in Python

Are we all writing code upside down? Don’t worry; I won’t ask you to tape your laptop to the ceiling or move to Australia. And yet, if I’ve learned anything in my first few years of software development, it’s that often the first-pass architectural solution to a software problem turns out to be the exact inverse of arguably the most robust design. Don’t just take my word for it; other more well-established software developers have espoused similar opinions, including Pythonista Brandon Rhodes, speaker Gary Bernhardt, and author Mark Seemann.
Out of respect for these important concepts, I will first discuss what has already been said about inverting our code; namely, that computational effects like I/O should be “hoisted” to the top of the system instead of remaining abstracted away at the bottom. This principle is innovative enough on its own, but I will next consider whether it can be generalized even further. Should we in fact be promoting all subroutines, regardless of their side effects, to higher levels in our system? The answer to this question remains to be seen. Let’s flip it all upside down and find out!
A well-intentioned disorientation
What do I actually mean when I say we write code “upside down”? This is just my own flashy phrasing of an already recognized anti-pattern, one which has borne a variety of descriptions over the years. Most lucid among these descriptions – the very inspiration behind this essay – is an account presented by Brandon Rhodes in a 2014 talk called “The Clean Architecture in Python”. In order to contextualize the rest of this discussion, I first must reiterate many of the ideas presented in that talk. That being said, I highly recommend experiencing the presentation firsthand, both to supplement this essay and on account of its own quality. (Seriously, do yourself a favor and watch it!)
Let’s first identify and diagnose a common method of architecting software. Consider the scenario of needing to use a web API as a data source. As an example, say I’d like to keep track of upcoming holidays via something like this public holiday API. In particular, I’ve decided to create a very basic command-line tool on top of this API that counts down the number of days until the next United States holiday, as seen in the following usage example:
$ python holiday_countdown.py
Only 2 more day(s) until Christmas Day!
Caching and other subtleties aside, my first-pass implementation might look something like this1:
def main() -> None:
next_holiday = fetch_next_holiday()
num_days = days_until(next_holiday)
holiday_name = next_holiday.name
print(f"Only more day(s) until !")
def fetch_next_holiday() -> Holiday:
"""Returns the soonest upcoming US holiday."""
this_year = date.today().year
next_year = this_year + 1
nearby_holidays = fetch_holidays(this_year) + fetch_holidays(next_year)
upcoming_holidays = filter(is_upcoming, nearby_holidays)
return min(upcoming_holidays, key=lambda holiday: holiday.date)
def fetch_holidays(year: int) -> List[Holiday]:
"""Fetches a collection of all US holidays in the given year."""
holiday_url = f"https://date.nager.at/api/v3/PublicHolidays//US"
holiday_data = requests.get(holiday_url).json()
return list(map(to_holiday, holiday_data))
def is_upcoming(holiday: Holiday) -> bool:
"""Returns whether the given holiday has not already occurred."""
return days_until(holiday) >= 0
def days_until(holiday: Holiday) -> int:
"""Returns the number of days until the given holiday."""
return (holiday.date - date.today()).days
def to_holiday(raw_holiday: HolidayDict) -> Holiday:
"""Maps a dictionary of raw holiday information into a Holiday."""
date_str = raw_holiday["date"]
date_ = date.fromisoformat(date_str)
name = raw_holiday["name"]
return Holiday(name, date_)
In most cases, I/O2 is incidental, rather than fundamental, to the domain of the encompassing project. Consequently, code that handles I/O tends to add incidental complexity to the codebase. This is visible in various places throughout implementation 1A: the particulars of the JSON schema of the returned data are unimportant, the choice of library we use to make HTTP calls is irrelevant, and the exact API endpoint we use may change as we adopt newer versions of the API3. None of these details have much relevance to the domain of comparing dates of US holidays; nevertheless, all of them need to be handled somewhere in the application. Without tending to these details carefully, a codebase can quickly devolve into spaghetti that is difficult to understand and maintain.
Faced with this impending scourge of incidental complexity, we software developers often
react by designing our code in the manner illustrated above. Namely, we apply the
principle of “abstraction”, via subroutines like fetch_holidays, so that higher-level
procedures like fetch_next_holiday need not concern themselves with the minutia of
URLs, JSON, and HTTP. Many such details are delegated away so that fetch_next_holiday
can remain at a consistent, high level of abstraction.
To its credit, many aspects of this design are admirable. At first glance, each procedure in the example is implemented at a consistent level of abstraction, appears to obey the single-responsibility principle well, and is arguably quite simple overall4. It even appears that it would be easy to modify the I/O-specific implementation details of the code without also affecting its more fundamental aspects. All in all, this design approach seems to successfully abate the scourge of incidental complexity, leaving us with highly readable and maintainable code.
Unfortunately, there is a fundamental flaw with this design, and it’s living surreptitiously inside the system’s dependency graph5:
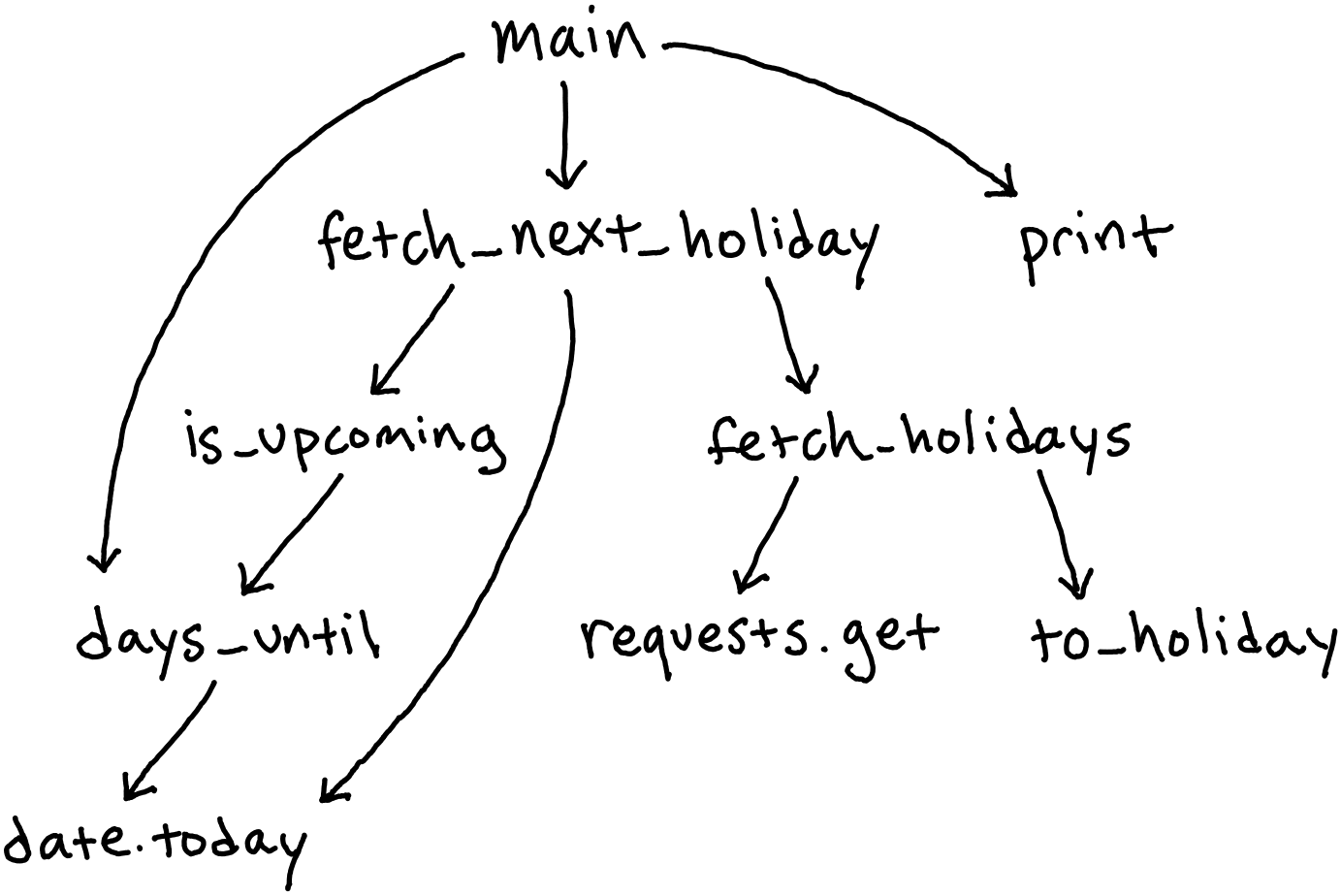
Notice that the requests.get I/O call, which connects to and retrieves data from the
holiday API, sits at the “bottom” of this connected graph. In other words, multiple
important procedures depend on this call; the system is strongly coupled to its I/O.
Hence, many such procedures cannot run, not even during testing, without an HTTP call
being made6. Due to the design of this system, there is simply no elegant way of
reliably verifying the correctness of core aspects of a procedure like
fetch_next_holiday without also undergoing the time-consuming and error-prone process
of connecting to the internet.
The fact that I am unable to test the mundane details of my code without also having to interact with the entire World Wide Web is precisely the issue this example is meant to illustrate. In his talk, Rhodes summarizes the dilemma well:
I/O is always a mess. Trying to talk to a database, trying to parse JSON, trying to get things in and out of a file – it’s a mess. It’s often very idiosyncratic code that doesn’t have a lot to do with the pure essence of what our programs are trying to accomplish and the characteristic error that we make is that we bury the I/O rather than cleanly and completely decoupling from it.7
This “characteristic error” is an all-too-common outcome of incautiously emphasizing abstraction in a system entrenched with I/O. Worse still, I suspect that popular development workflows like test-driven development, when practiced naively (as is often the case), only serve to entrench this kind of design: if I interpret “red, green, refactor”, as just “implement, execute, extract procedures”, my code gravitates towards this state in which the I/O is visually isolated from, but remains functionally tightly coupled to, the rest of the system8. By combining this bad practice with these misunderstood principles, the unassuming or even well-intentioned developer often leaves their system worse off than how they found it.
So how do we dig ourselves out of this mess? Again, Rhodes explains succinctly:
[Put] I/O at the top level of your program instead of at the bottom.9
In other words, our code is upside down, and we need to flip it on its head!
Turn that I/O upside down
Over the years, the remedy to the ailment of upturned code has been served in a variety of descriptions. Many of these perspectives are useful and insightful in their own way, so I will summarize them soon. However, I expect that the most illustrative introduction may be in the form of an example. Consider the following revised implementation of the previous program1:
HOLIDAY_URL_TEMPLATE = "https://date.nager.at/api/v3/PublicHolidays/{}/US"
def main() -> None:
today = date.today()
urls = build_nearby_holiday_urls(today)
holiday_pages = list(map(lambda url: requests.get(url).json(), urls))
nearby_holidays = to_holidays(holiday_pages)
next_holiday = find_next_holiday(today, nearby_holidays)
num_days = days_after(today, next_holiday)
holiday_name = next_holiday.name
print(f"Only more day(s) until !")
def build_nearby_holiday_urls(date_: date) -> Collection[str]:
"""Returns urls for fetching US holidays near the given date."""
current_year = date_.year
next_year = current_year + 1
years = (current_year, next_year)
return list(map(HOLIDAY_URL_TEMPLATE.format, years))
def to_holidays(
raw_holiday_pages: Collection[Collection[HolidayDict]],
) -> Collection[Holiday]:
"""Maps multiple raw holiday pages into a collection of Holidays."""
raw_holidays = [holiday for page in raw_holiday_pages for holiday in page]
return list(map(to_holiday, raw_holidays))
def to_holiday(raw_holiday: HolidayDict) -> Holiday:
"""Maps a dictionary of raw holiday information into a Holiday."""
date_str = raw_holiday["date"]
date_ = date.fromisoformat(date_str)
name = raw_holiday["name"]
return Holiday(name, date_)
def find_next_holiday(
date_: date, nearby_holidays: Collection[Holiday]
) -> Holiday:
"""Finds the next holiday in the given collection after the given date."""
is_upcoming = lambda holiday: is_after(date_, holiday)
upcoming_holidays = filter(is_upcoming, nearby_holidays)
return min(upcoming_holidays, key=lambda holiday: holiday.date)
def days_after(date_: date, holiday: Holiday) -> int:
"""Returns the number of days between the given date and holiday."""
return (holiday.date - date_).days
def is_after(date_: date, holiday: Holiday) -> bool:
"""Returns whether the given holiday occurs on or after the given date."""
return days_after(date_, holiday) >= 0
At first glance, this revision may not appear any better than the previous version. Once again, however, the most important aspect of this code lies hidden in its dependency graph:
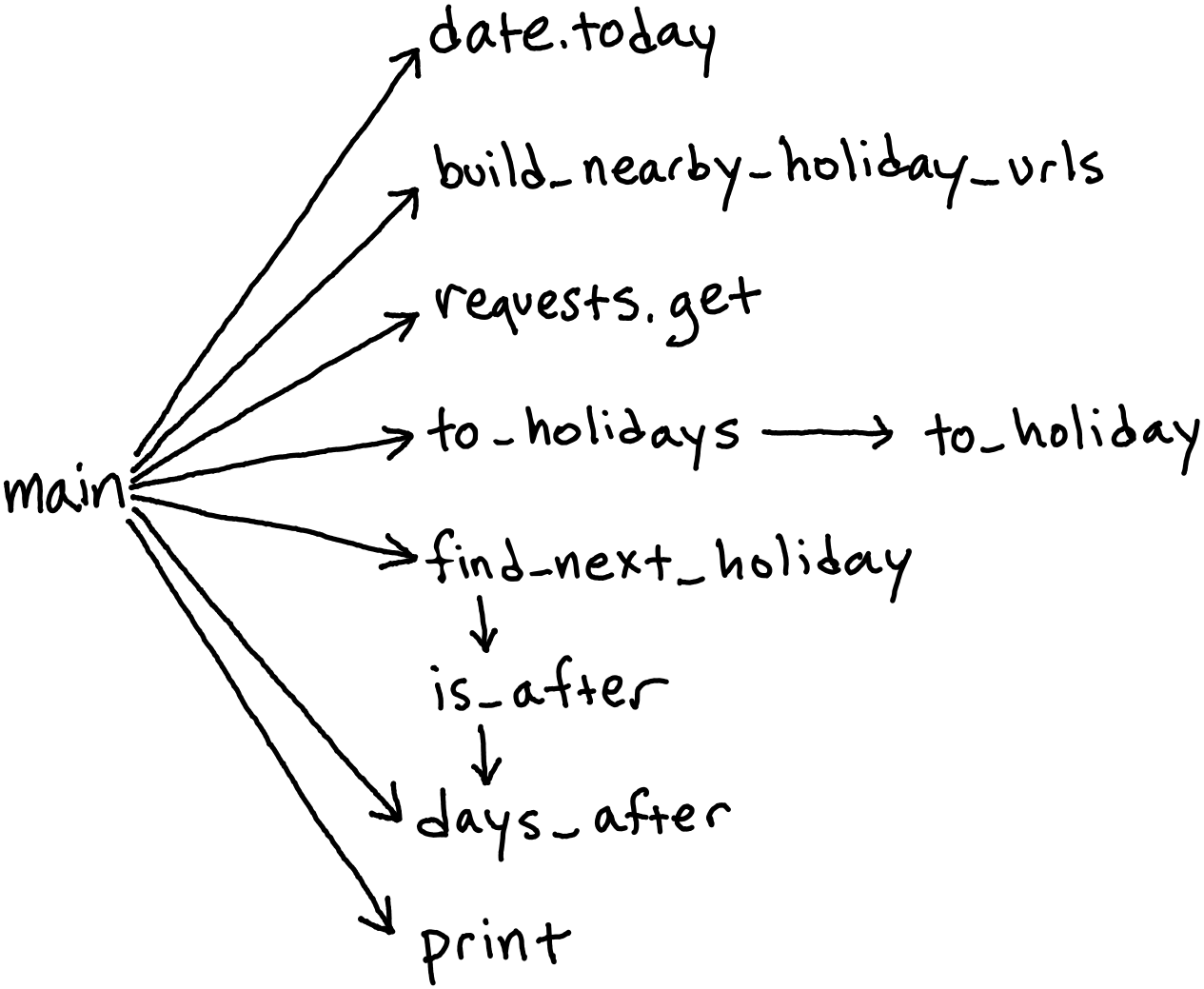
Clearly, this graph greatly differs from the previous one; so much so that it is more
easily depicted on its side (that is, with dependencies pointing from left to right).
This is primarily due to the more important fact that almost all dependencies have the
main procedure as the caller. Most important of all, we see that all of the I/O (in
particular, requests.get) is now a direct dependency of the main procedure, and of
nothing else. In other words, the I/O is no longer buried at the bottom of the
application; it has now risen to the surface. The primary goal of the previous approach
was to “abstract” away the complexity inherent in I/O by burying it at the bottom of the
system. This approach turns that idea on its head by bringing I/O all the way to the
top.
In what ways does this architecture improve on that which emphasized abstraction via
subroutines? In short, the system is now almost entirely decoupled from its I/O, which
dramatically improves testability, reusability, and even, as I will argue,
simplicity10. First, notice that every procedure other than main is now a pure
function11 with simple data types as inputs and outputs. Let’s consider the
ramifications of a system that is almost entirely composed of simple, pure functions.
Improved testability
The biggest improvement is in testability, both manual and automated. Consider the
task of testing find_next_holiday from implementation 1B. With simple inputs and
outputs and with no side effects, testing a function like this requires nothing more
than handing it example data and verifying your expectations. Nothing else is required
– no setup, teardown, mocks, or patches needed! In the end, you’ll find that your tests
are concise, repeatable, and extremely fast. Contrast this with fetch_next_holiday
from implementation 1A, which effectively cannot be run without an internet connection,
and whose output depends on the day you run it! Needless to say, testing
fetch_next_holiday, no matter how you attempt it, is no holiday.
Improved reusability
More generally, decoupling a system from its I/O results in more reusability. (Improved testability can actually be viewed as just a particular case of this.) For an explanation of this, I will defer to Brandon Rhodes:
Initially our subroutine was coupled to the kind of I/O that the program was originally written for… With this maneuver of changing the subroutine into something that simply speaks the language of data and hands that data back, we have now hoisted our I/O up to the top level of the program, leaving the subroutine purely in charge of doing data operations. I generally find that this gives me subroutines that are far easier to use and reuse, as my team comes up with new requirements, than the subroutines that go ahead and perform their own I/O and thus remain very closely coupled to a single context of use.12
If one day I decide I want to fetch holiday data from a database instead of a web API, I will probably find it more difficult to update implementation 1A than to update implementation 1B, because everything in the former implementation is founded on the assumption that data comes from a web API. By instead choosing to decouple I/O from my application’s core functionality, as in the case of implementation 1B, I leave the door open to other approaches in the future.
Improved simplicity
Finally, I also believe that decoupling I/O in this manner even results in greater
simplicity. In my opinion, while the subroutines of the initial approach only feign
compliance with the single-responsibility principle, the functions of the new design
actually do comply. The subroutine fetch_next_holiday, for instance, both fetches and
filters data – two orthogonal concerns – whereas find_next_holiday only filters. And,
since each function in implementation 1B is so simple and single-minded, we can easily
compose these transformations into a linear sequence of steps at the top. Hence, the new
main procedure, despite its verbose appearance, incurs little in added complexity from
these changes. Once again, Brandon Rhodes summarizes this well:
This approach continually surfaces intermediate results that can be checked and examined. If you find that this [implementation] doesn’t work, you can just go back and find at which step it failed…13
In the first example, if fetch_next_holiday fails at runtime, it is unclear whether I
should pinpoint the cause on a bug in the filtering logic or on an I/O issue in one of
its subroutines. If find_next_holiday fails, on the other hand, I can confidently
expect the cause to be a filtering issue.
By resisting the natural inclination to bury I/O and instead bringing it to the surface of our architecture, we reap the benefits of improved testability, reusability, and simplicity throughout the life span of the application. With such a powerful value proposition, it’s no surprise that the principle of “turning I/O upside down” appeals to experts like Brandon Rhodes. By further listening to these experts, we can gain even more insight into this pattern and its manifestations.
Appealing to the experts
Alas, I cannot take any credit for this design pattern. Many before me have extolled this concept, potentially even more convincingly so than I have. Among them include of course Brandon Rhodes, but also Gary Bernhardt of Destroy All Software, author Mark Seemann, and even the creators of the programming language Haskell. Since each expert offers their own illuminating take on the subject, I will provide a survey of their ideas here.
Brandon Rhodes: “Hoist” your I/O
Top of mind, of course, is Brandon Rhodes, whose aforementioned 2014 talk perfectly elucidated this pattern, but also classified it as a specific case of Robert C. Martin’s “clean” architecture. But even more evocative, in my opinion, is his coinage of the phrase “hoisting your I/O” in a 2015 follow-up talk of the same name. “Hoisting”, in this sense, refers to that process by which I/O is elevated from deep within nested subroutines to the top level of the program. As I’ve already explained, this frees up procedures, once tightly coupled to said I/O, to be reused more easily.
Gary Bernhardt: “Functional Core, Imperative Shell”
In his 2014 talk, Brandon Rhodes cites another notable distillation of this pattern, one by Gary Bernhardt. To Bernhardt, this is all known as “functional core, imperative shell”. In this formulation, the system is divided into two parts. First, there is the “functional core”, which consists solely of isolated, purely functional components that implement the system’s core business logic. Surrounding this core is the portion known as the “imperative shell”, a “thin layer of adapters”14 acting as “procedural glue”15, by integrating the functional components, as well as mediating between them and the outside world. Bernhardt provides a very tidy presentation of this and its related concepts in his wonderful PyCon 2015 talk “Boundaries”16.
With hope, it is not too difficult to see how Bernhardt’s ideal architecture is realized
in implementation 1B. In that example, the imperative shell consists solely of the
main procedure, while the core logic is extracted into pure functions like
find_next_holiday. From this new vantage point, we now see how our main procedure
acts as a “thin” shell of procedural “glue” code: it lacks many paths, it handles the
idiosyncrasies of I/O, and it integrates all the other procedures into a coherent
sequence of steps.
Mark Seemann: Functional Architecture
Towards the end of his own talk, Gary Bernhardt recognizes similarities between his
formulation and another, symbolized by the IO type constructor in the programming
language Haskell. This latter perspective is the formulation of choice for author Mark
Seemann. As Seemann might argue, everything discussed so far ultimately converges under
a single unified perspective on functional architecture, and that architecture is best
codified in Haskell’s unique type system.
To understand the perspective offered by Seemann, it is important to have a little
background on Haskell itself. For those who are unfamiliar,
Haskell is a statically typed, functional programming
language. One of its most notable features, both in relation to this discussion and in
general, is its opinionated treatment of I/O. Included in Haskell’s type system is a
special parameterized type called IO (parameterized, meaning that it occurs as part of
concrete types like IO String and IO (). In Python, these types are somewhat
analogous to IO[str] and IO[NoneType], respectively.) There are two things to note
about this type. First, every core procedure in Haskell that performs I/O has IO in
its type signature. Second, if one procedure has IO in its type signature, and a
second procedure depends on the first, then the second procedure must also must have
IO in its type signature (any assertion to the contrary made by the programmer results
in a compile error). In other words, IO is contagious; it is inherited by every
procedure that interacts with the outside world, directly or indirectly. As it turns
out, this fact has important implications for how Haskell code is naturally organized.
Let’s consider how these language features would affect implementations 1A and 1B if
they were both ported to Haskell. First, in both implementations, the type signature of
main would actually be the same, namely IO (). This, however, is where the
similarities would end. In implementation 1A, nearly every other procedure would have
IO in its type signature, while in 1B, not a single other procedure would. As an
example (illustrated below), the type signature of fetch_next_holiday would be IO
Holiday, but that of find_next_holiday would be Day -> [Holiday] -> Holiday (this
means it takes a Day and a list of Holidays as arguments and returns a single
Holiday). Here, Haskell’s type system is telling us that fetch_next_holiday
interacts with the outside world, while find_next_holiday does not. Put plainly, this
hypothetical reveals the contagion of IO in practice. Even though the first
architecture pretends to hide its I/O out of sight, the Haskell compiler recognizes
this for what it really is: contaminating the entire system with I/O.
-- Returns the soonest upcoming US holiday.
fetchNextHoliday :: IO Holiday
fetchNextHoliday = do
(thisYear, _, _) <- toGregorian <$> utctDay <$> getCurrentTime
let nextYear = thisYear + 1
nearbyHolidays <- (++) <$> fetchHolidays thisYear <*> fetchHolidays nextYear
upcomingHolidays <- filterM isUpcoming nearbyHolidays
return (minimumBy compareDates upcomingHolidays)
where
compareDates holiday1 holiday2 = (date holiday1) `compare` (date holiday2)
-- Finds the next holiday in the given collection after the given date.
findNextHoliday :: Day -> [Holiday] -> Holiday
findNextHoliday date_ nearbyHolidays = minimumBy compareDates upcomingHolidays
where
isUpcoming = (`isAfter` date_)
upcomingHolidays = filter isUpcoming nearbyHolidays
compareDates holiday1 holiday2 = (date holiday1) `compare` (date holiday2)
fetch_next_holiday and find_next_holiday ported
to Haskell. The type signatures (first lines) of each procedure reveal that
find_next_holiday is a pure function, while fetch_next_holiday involves I/O.This demonstrates how Haskell’s type system is tailor-made to expose code that is contaminated by I/O. As explained in Learn You a Haskell by Miran Lipovača:
If we’re taking data out of an I/O action, we can only take it out when we’re inside another I/O action. This is how Haskell manages to neatly separate the pure and impure parts of our code.17
The principle that, by definition, only impure procedures can call other impure procedures is what Mark Seemann refers to as the “functional interaction law”18. By codifying this law into its type system, Haskell lays bare the fact that within every codebase there exists an inherent demarcation between pure functions and impure procedures. From this perspective, the big difference between implementations 1A and 1B is in how much emphasis they place on either side of that demarcation line.

As far as I know, the Haskell compiler doesn’t itself make any value judgments about the quality of your code. However, as you may have already inferred, the functional programming paradigm is quite partial to code that minimizes the permeation of I/O throughout a system. Mark Seemann makes clear how silly it would be to actually write implementation 1A in Haskell:
You can trivially obey the functional interaction law by writing exclusively impure code. In a sense, this is what you do by default in imperative programming languages. If you’re familiar with Haskell, imagine writing an entire program in
IO. That would be possible, but pointless.18
In practice, Haskell’s type system implicitly encourages the developer to respect
functional programming best practices and avoid careless use of IO. And, since the
IO type is inherited from subroutines, the evident way to limit the spread of IO is
to hoist it out of subroutines, to the top of the system. In other words, the very
principle espoused by this essay is but a natural consequence of Haskell’s type system!
In this way, Haskell may be one of the only languages in which it is more natural to
write I/O code that isn’t “upside-down” in the first place. Mark Seemann’s words are
once again apropos:
In Haskell programming, you should strive towards maximizing the amount of pure functions you write, pushing the impure code to the edges of the system. A good Haskell program has a big core of pure functions, and a shell of
IOcode. Does that sound familiar?19
This should sound very familiar indeed; it is almost exactly the description used by Gary Bernhardt! And so we have come full circle. Mark Seemann describes this as the ideal “functional architecture”18, Gary Bernhardt refers to it as “functional core, imperative shell”, Brandon Rhodes calls it “hoisting” your I/O, and I call it turning your I/O “upside down”.
Regardless of which description you prefer, each one essentially describes and recommends the same pattern: don’t bury I/O at the bottom of the system where it can wreak havoc from below. Instead, push it to the boundary (i.e. the very top) of the system and you will end up revealing a robust and reusable functional core that was hiding below all along!
A ScapegI/Oat?
Now, you might reckon that this would be a good place to conclude, and you’d probably be right. And yet, the real reason I chose to write this essay is that, despite wholly agreeing with this pattern and the many narratives surrounding it, I still had this nagging feeling that something was missing, or at least underemphasized, within it. What if, despite all evidence to the contrary, much of the blame levied on I/O in this discussion is misdirected? What if there is another anti-pattern hiding in plain sight, even more prevalent than I/O, which truly deserves the blame for creating upside-down code? Join me as I plunge one more time into the depths of our code in search of something that even the others may have overlooked.20
Assisting us in this dive, we have yet another code example. The following program is slightly different from the previous two. In honor of Twosday, which, as of writing this, graced our calendars a little more than two months ago, I am no longer interested in public holidays, but rather dates which (when written in standard US date notation) exhibit satisfying numeric patterns, like 2/2/22 and 4/3/21. Here is a usage example:
$ python special_dates.py
Today is 2/2/22, what a special date!
Once again, my first-pass implementation might look something like this21:
ORDINARY_MSG_END = "just an ordinary date."
SPECIAL_MSG_END = "what a special date!"
def main() -> None:
# Imperative shell
today = date.today()
# Functional core
msg = create_msg(today)
# Imperative shell
print(msg)
def create_msg(date_: date) -> str:
"""Returns a message describing whether the given date is "special"."""
msg_end = SPECIAL_MSG_END if is_special(date_) else ORDINARY_MSG_END
return f"Today is , "
def is_special(date_: date) -> bool:
"""Returns whether the given date is considered "special"."""
return consists_of_single_digit(date_) or has_sequential_digits(date_)
def consists_of_single_digit(date_: date) -> bool:
"""Checks whether the date in US date format consists of a single digit."""
return len(set(digits(date_))) <= 1
def has_sequential_digits(date_: date) -> bool:
"""Checks whether the date in US date format has sequential digits."""
digits_ = digits(date_)
pairs = pairwise(digits_)
differences = map(difference, pairs)
difference_vals = set(differences)
return difference_vals in ({1}, {-1})
def digits(date_: date) -> List[int]:
"""Returns the integers comprising the US date format of the given date."""
digit_str = f""
return list(map(int, digit_str))
def difference(pair: Tuple[float, float]) -> float:
"""Returns the difference between the second and first item in the pair."""
x, y = pair
return y - x
The first thing worth noting about this code is that it involves almost no I/O interaction (nor any other computational effects, to boot), and the little I/O that it does have is dutifully “hoisted” to the top, forming a model example of “imperative shell, functional core”. Therefore, of all the perspectives considered so far, none would make a case for further refactoring this design. And despite this, when we once again take a look at the system’s dependency graph, we begin to notice some resemblance:
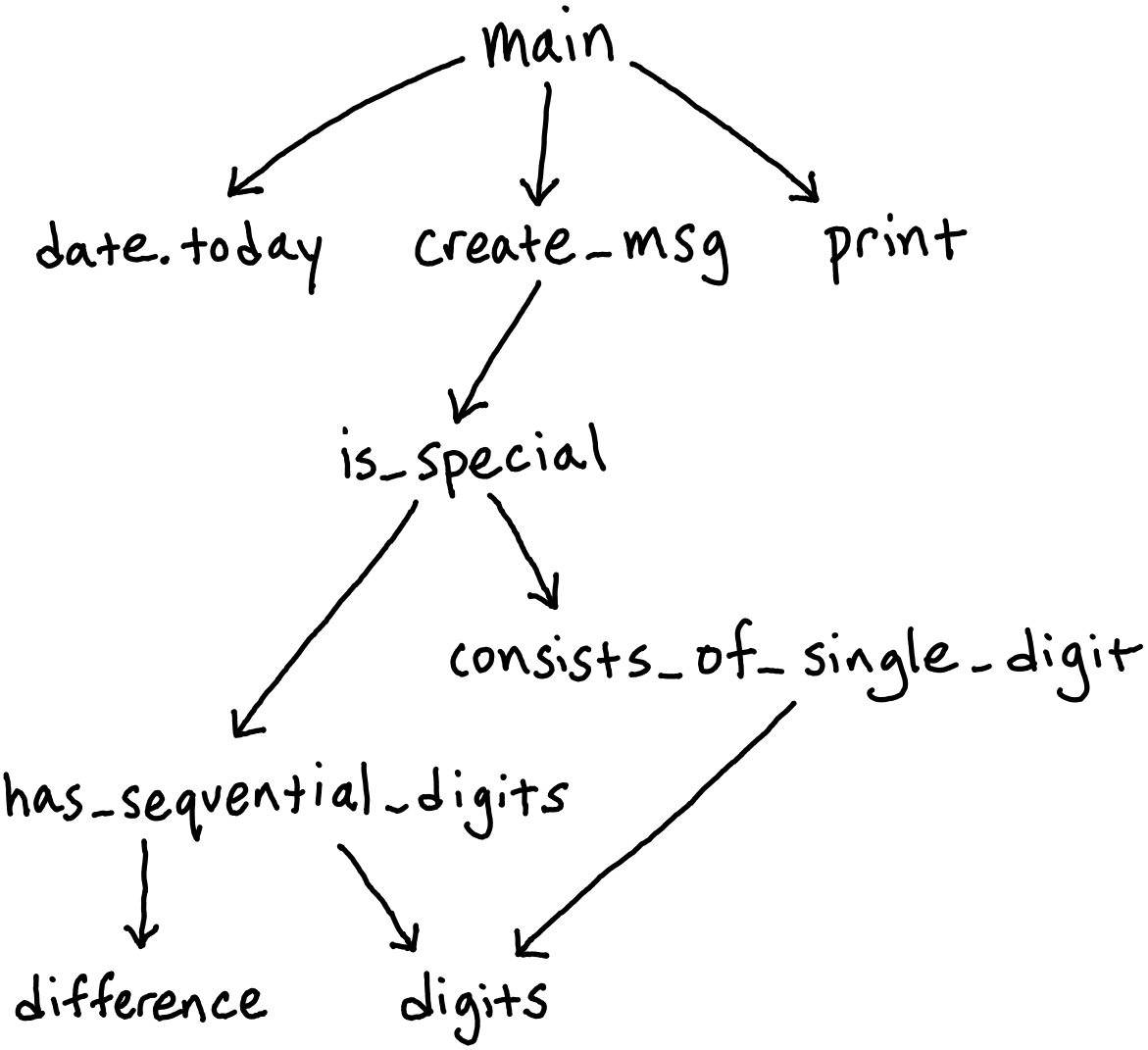
Much like the dependency graph of implementation 1A, this graph is hierarchical in
structure. Similar to how requests.get sat at the “bottom” of the first dependency
graph, at the bottom of this graph lies digits, with almost everything else in the
system depending on it. Many important functions cannot run, not even during testing,
without also calling this function. These are almost the same observations that we made
about the first graph prior to recognizing its own architectural flaws. This time,
however, the advice we’ve learned doesn’t exactly apply. So what gives?
Of course, there is an important difference between the two graphs! Namely,
requests.get is an I/O operation, while digits is a pure function. We’ve already
belabored the fact that I/O is non-deterministic, time-consuming, idiosyncratic, and
error-prone, while pure functions embody the antithesis of this. A deep tree of
dependencies that is nevertheless composed of fast and robust functions is a far cry
from one founded on slow and error-prone code. So maybe there is no issue with the
design of implementation 2A after all. Maybe this design is fine, precisely because none
of the existing dependencies are built atop I/O operations.
I, however, do not find this explanation entirely persuasive. We now recognize that
implementation 2A bears a resemblance to implementation 1A, a design that we now
recognize as flawed. It seems incongruous to maintain that a hierarchical dependency
structure, which both implementations exhibit, is a valid design, just so long as the
“bottom” of the graph doesn’t happen to perform any I/O operations. A procedure like
is_special might not currently depend on an external data source to function, but
this may change as new software requirements are requested. Should we really conclude
that it’s fine for create_msg to depend on is_special for now, but possibly not
sometime later?
I do not believe it is sensible to hold that the quality of such a fundamental architectural design is context-dependent on the erratic whims of bespoke software requirements. I suspect that I/O is not actually fundamental to the issue of upside-down code, but rather an incidental complication that primarily serves to compound a pre-existing condition. After all, if I/O really was the fundamental problem, then the solution would have been to remove it altogether rather than just reorganize it. The real culprit appears to reside more in the structure of the code than in its function. In other words, I believe that the above design retains many of the ill-advised qualities of “upside-down” code, even as it happens to avoid the fatal mistake of burying I/O. Similar flaws as before remain; they are just significantly more subtle.
With apologies for the clickbaity subtitle, I admit that I/O is not a complete scapegoat for our problems. The anti-pattern of burying I/O is a legitimate one, and it is largely due to the aforementioned complexities inherent in it. It is no accident that a language like Haskell gives I/O special treatment in its type system. Nevertheless, there is yet another concept that is even more fundamental to upside-down code than I/O, and it has still largely evaded our attention. Up next: I cross-examine the humble subroutine.
Subroutine considered harmful?
In my opinion, the essence of implementation 2A (as well as of implementation 1A) lies
in its heavy reliance on subroutines, in an effort to achieve maximal abstraction.
This abstraction is present in two places. First, each procedure provides a concise and
seamless signature by hiding all intermediate computation details within its body.
Second, each procedure maintains a consistent level of abstraction inside its body by
delegating lower-level computation details to other subroutines. For example, in
implementation 2A, the interface create_msg(date_: date) -> str is incredibly
straightforward: it receives a date and returns a message. From the perspective of any
callers, precisely how create_msg constructs a message from the given date is unknown
and unimportant, which makes it extremely easy to use. The body of create_msg is also
straightforward. By delegating the details of what makes dates “special” to
is_special, it can focus on its primary objective of constructing a customized
message. This yields a function body that is simple and readable, and once again appears
to obey the single-responsibility principle well.
Abstraction, when reaped in this way, immediately yields low-hanging fruit in the form of usable and readable function signatures and bodies. This, I believe, is why many well-intentioned developers (including, until recently, myself) initially gravitate toward this approach. Unfortunately, due to its reliance on subroutines to achieve these benefits, this design also makes a subtle tradeoff. Subroutines, by their very nature, are inextricably associated with tight coupling. The very act of referencing one procedure within another necessarily couples the caller to the callee. It is impossible to call the former without also calling the latter, and this coupling lies at the root of many other programming afflictions. Most notably, the caller cannot be used independently of the callee, and the callee’s behavior cannot be modified independently of the caller’s.
Furthermore, these problems are only compounded when this approach is used recursively,
as exemplified in the previous implementation. Notice how create_msg calls
is_special, which in turn calls consists_of_single_digit, and so on. With such a
deep tree of dependencies, the inability to run create_msg as an independent component
is only exacerbated. And ironically, a deep dependency graph is often what results when
this kind of abstraction is earnestly administered consistently throughout a codebase.
The prioritization of simple function signatures and bodies at every level of the system
inevitably leads to the use of subroutines at each level, which in turn causes a
function like create_msg to become tightly coupled to almost everything else in the
system. Hence we see that even a slight preference for abstraction via subroutines can
lead to a painfully monolithic design.
Previously, we conceded that none of the recommendations considered so far are directly applicable to improving implementation 2A. And yet despite this, what if we were to follow the spirit of all previous advice and refactor our code anyway? After refactoring in this way, we might produce the following implementation21:
ORDINARY_MSG_END = "just an ordinary date."
SPECIAL_MSG_END = "what a special date!"
def main() -> None:
# Imperative shell
today = date.today()
# Functional core
digits_ = digits(today)
consists_of_single_digit = consists_of_single_val(digits_)
is_sequential_ = is_sequential(digits_)
is_special_ = is_special(consists_of_single_digit, is_sequential_)
msg = create_msg(today, is_special_)
# Imperative shell
print(msg)
def digits(date_: date) -> List[int]:
"""Returns the integers comprising the US date format of the given date."""
digit_str = f""
return list(map(int, digit_str))
def consists_of_single_val(xs: Collection[Hashable]) -> bool:
"""Checks whether the collection consists of a single "repeated" value."""
return len(set(xs)) <= 1
def is_sequential(nums: Sequence[float]) -> bool:
"""Checks whether the sequence is increasing or decreasing by exactly 1."""
pairs = pairwise(nums)
differences = map(difference, pairs)
difference_vals = set(differences)
return difference_vals in ({1}, {-1})
def difference(pair: Tuple[float, float]) -> float:
"""Returns the difference between the second and first item in the pair."""
x, y = pair
return y - x
def is_special(consists_of_single_digit: bool, is_sequential_: bool) -> bool:
"""Computes whether the given properties amount to being "special"."""
return consists_of_single_digit or is_sequential_
def create_msg(date_: date, is_special_: bool) -> str:
"""Returns a message describing whether the given date is "special"."""
msg_end = SPECIAL_MSG_END if is_special_ else ORDINARY_MSG_END
return f"Today is , "
Let’s once again take a look at the dependency graph of this implementation.
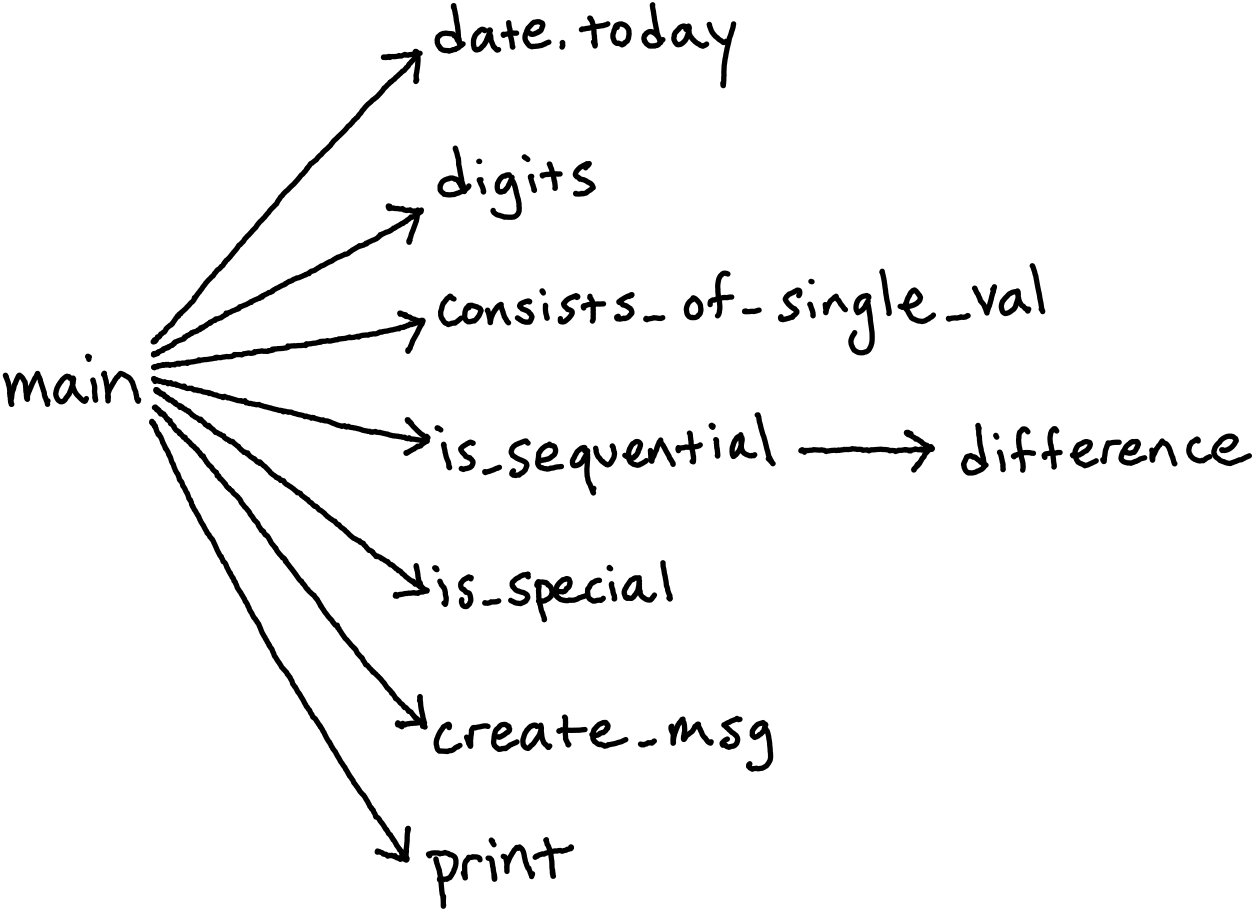
Yet again, the previously hierarchical structure has been significantly flattened.
Almost all dependencies have the main procedure as the caller, and the digits
function has now been hoisted to the surface of the application architecture. In
contrast to implementation 2A, which buried many details under a deeply nested hierarchy
of subroutines, implementation 2B takes an antipodal approach and surfaces nearly
everything (within reason) to the top.
What are the ramifications of using this approach? Is it strictly better than the previous one? Unfortunately, the answer is not as straightforward as in the case involving I/O, but there is a lot to learn from comparing these two architectures, and ultimately I do believe that this one improves on its predecessor in some subtle but important ways.
To understand these improvements, let us compare how the implementations of create_msg
and is_special differ between implementations 2A and 2B. Once again, we will measure
these two approaches against the properties of testability, reusability, and simplicity.
First of all, notice that, in implementation 2B, both create_msg and is_special
replace direct subroutine calls with function parameters intended to receive what these
calls would return. So, instead of create_msg calling is_special directly, the
result of is_special is passed to create_msg as an argument after is_special has
been called separately (in particular, by main). With this in mind, let us now examine
the ramifications of this refactored design on testability.
Improved testability
Below is a simple test22 of implementation 2A of create_msg. This test verifies our
expectations of the function’s output for two representative dates.
ORDINARY_DATE = date(2012, 12, 12)
ORDINARY_DATE_EXPECTED_MESSAGE = "Today is 12/12/12, just an ordinary date."
SPECIAL_DATE = date(2021, 4, 3)
SPECIAL_DATE_EXPECTED_MESSAGE = "Today is 4/3/21, what a special date!"
def test_create_msg():
assert create_msg(ORDINARY_DATE) == ORDINARY_DATE_EXPECTED_MESSAGE
assert create_msg(SPECIAL_DATE) == SPECIAL_DATE_EXPECTED_MESSAGE
In many ways, this is a great test. It is concise, simple, and will execute very
quickly; such qualities are emblematic of testing pure functions. Unfortunately, these
features also overshadow some shortcomings of testing this particular implementation.
Since this implementation of create_msg is directly dependent on is_special, any
test of the former will also implicitly be a test of the latter. To see what this means,
consider the following scenario of evolving software requirements. One day, some
interested party decides that 12/12/12 really should be considered special, while
4/3/21 is actually rather mundane. Obviously, both is_special and any of its own tests
will have to be updated, but what about create_msg? Unfortunately, such changes indeed
break the above test, for not only has the significance of these dates changed, but also
the messages associated with them. We’ve discovered that, even though we might think of
create_msg as a simple string formatter, it also secretly serves as an arbiter of
dates. Any time is_special changes its behavior, this has a direct effect on both
create_msg and its tests.
On the other hand, consider the effect that this scenario would have on implementation
2B of create_msg and this corresponding test:
def test_create_msg():
assert create_msg(ORDINARY_DATE, False) == ORDINARY_DATE_EXPECTED_MESSAGE
assert create_msg(SPECIAL_DATE, True) == SPECIAL_DATE_EXPECTED_MESSAGE
Pleasingly, this test is not broken by our changing requirements. Since the
significance of each date is now parameterized, create_msg is no longer directly
concerned with what the function is_special has to say about 12/12/12 or 4/3/21. This
decoupling frees up create_msg to truly focus solely on message creation, which in
turn means that test_create_msg can now really test create_msg all by itself.23
Next, let’s turn to is_special itself, and once again compare how these
implementations affect its tests. Similarly to create_msg, implementation 2B of
is_special also trades out direct subroutine calls for parameters that receive the
results of these calls. For is_special, however, the consequences of this are slightly
different. Consider now how these changes in input parameters affect the input domain
of this function. In the version of is_special from implementation 2A, the domain is
the set of all valid dates, including date(1970, 1, 1), date(2021, 4, 3), and even
date(9997, 2, 3) (my 8000th birthday!). Clearly, the input domain for this function is
incredibly large – in principle even infinite! (However, in practice it is restricted by
factors such as the limitations of Python’s date class.) Furthermore, attempting to
find a small set of representative elements for this domain is not necessarily trivial.
Should date(2045, 12, 3) be considered a different test case than date(2045, 1, 23),
or do they both represent the same type of “special” date? All this is to say, testing
this implementation thoroughly is somewhat difficult, while testing it exhaustively is
nearly impossible.
Contrast this with the task of testing the version of is_special from implementation
2B. This function has two parameters, each of type bool. This renders the input domain
of this function extremely small – so small, in fact, that we can enumerate it in its
entirety right here: (True, True), (True, False), (False, True), and (False,
False). Hence, not only are we able to test this function thoroughly, we can even test
it exhaustively, and all in a fraction of a millisecond! By pulling out the dependencies
of this function into parameters, we significantly restrict the input domain of
is_special, which drastically improves its testability in turn.
Improved reusability
I’ve contended previously that testability is just a special case of reusability, so it
might not come as a surprise that these improvements in testability go hand in hand with
broader improvements in reusability. This can again be seen in the decoupling of
both create_msg and is_special. In implementations 2A and 2B, we are no longer
concerned that is_special conceals undesirable I/O within its ranks. Even so, by
coupling this function to create_msg, implementation 2A relinquishes the option to
procure information about the significance of dates from anywhere else. This rules out
many promising variations, such as caching and memoization, additional implementation
strategies, or alternative
interpretations of what makes a date “special”. On the other hand, the implementation 2B
version of create_msg, which parameterizes the considerations of is_special, is
agnostic of all of these idiosyncrasies by definition and is, therefore, able to
interoperate with all of them easily. More generally, in the refactored architecture of
implementation 2B, functions like is_special and create_msg serve as independent
atoms of a modular system; they can be combined and interchanged in a variety of ways
without ever needing to be modified internally. This is textbook reusability on display,
and it characteristically leads to highly nimble and adaptable systems.
There is one additional measure of reusability which I wish to highlight, in part
because it reveals a notable blind spot for all of the previously discussed frameworks;
namely, “functional core, imperative shell”, “hoisting your I/O”, and even Haskell’s
IO type. One problem with these frameworks is that they concentrate on the problem of
existing I/O while overlooking the more subtle issue of potential I/O. By
“potential” I/O, I refer to the fact that, as software requirements grow and change,
units of a program that previously involved no I/O interaction might later become
encumbered with or even replaced by I/O. This is an understated issue, as it admits the
possibility of an otherwise well-organized architecture acquiring deep-rooted I/O after
just a couple code changes. Imagine: the special dates project manager has just decided
that the significance of a date should now be outsourced to a web API maintained by
another team. Suddenly, is_special is no longer some unremarkable functional
component, but rather an adapter for a complex network-attached data source, with all
the complexity that implies. For an unprepared architecture like that of implementation
2A, this change amounts to an existential blow for an otherwise strong functional
design. Once is_special encapsulates I/O operations, this immediately also
contaminates create_msg, and suddenly this architecture begins to look more like a
counterexample than a role model for functional design.
Fortunately, the problem of potential I/O is handled quite elegantly by the flat
architecture of implementation 2B. When using this implementation, if our project
manager indeed asks us to redesign is_special as an adapter for an external web API,
we can rest assured that this change will fit cleanly into the existing design. Notice
that is_special already sits at the topmost level of the program (excluding main
itself), so it can be adjusted from pure function to impure procedure without affecting
the overall “functional core, imperative shell” design. This is a profound advantage of
the flat architecture: not only does it minimize the contamination of actual I/O
throughout the system, it also reduces the danger imposed by potential I/O at any time
in the future. As we have seen, this is not true of every functional design (such as
that of implementation 2A). Rather, it appears to be a unique benefit of the design
which minimizes its reliance on subroutines, as any such subroutine threatens to one day
be contaminated with I/O.
Improved simplicity
The final property that we will examine is simplicity. On this front, many of the
improvements presented in the earlier context of hoisting I/O also apply here. Case in
point: the refactored version of create_msg better complies with the
single-responsibility principle than its precursor, because it exclusively deals with
message creation. Furthermore, since each function is more independent and
single-minded, this allows us to compose them into a simple linear sequence of steps
inside main. If anything goes wrong in this pipeline, it is easy to both pinpoint
which function erred, and fix it without disturbing the rest of the system. These are
all benefits that we identified previously, but they ring just as true now, even as I/O
remains absent from the picture.
On top of all these benefits, I would like to add one final, more aesthetic perspective
on simplicity. In my opinion, the true beauty of parameterizing both the significance of
dates within create_msg, and the properties of significant dates within is_special,
is that these implementations become not merely refactorings of their predecessors,
but rather generalizations. While the first implementation of create_msg needlessly
concerns itself with the trivialities of the is_special function, the second
implementation implicitly recognizes that the true significance of any particular date
lies in the eyes of the beholder, and that beholder very well may not always be the
current, specific implementation of is_special. Similarly, by shifting the focus to
properties of dates (namely, that of “consisting of a single digit” and of “being
sequential”) rather than dates themselves, the second version of is_special captures
an insightful realization: it’s not necessary to know the particular date in question in
order to determine whether it’s special! When refactored according to this revelation,
is_special arguably more clearly encodes precisely what it means for a date to be
“special”, and it does so independently and economically as well. Along with many of the
other functions in this implementation, the versions of create_msg and is_special
that intentionally forgo the use of subroutines not only fortuitously introduce more
testability, reusability, and simplicity into the system, they actually serve as a more
enlightened model of the system they implement. And it seems no accident to me that
such a stronger conceptual model invariably brings a wide variety of ancillary benefits.
So is all this to say that subroutines should always be considered harmful?
Unfortunately, the answer is just not that simple. Replacing subroutines usually comes
with tradeoffs, and many times it is not even possible to do so. Even implementation 2B
contains an extra internal dependency between is_sequential and difference, and we
have conveniently ignored the existence of external dependencies to functions like
len, map, and even or. And even after putting aside these arguably inextricable
dependencies, there are still downsides to an architecture like that of implementation
2B as compared to that of implementation 2A. First and foremost, implementation 2B tends
to emphasize decoupling at the expense of abstraction. For example, when comparing
main procedures, it is difficult to maintain that the complex pipeline approach of
implementation 2B is remotely as intuitive as the one-line functional core of
implementation 2A. On a similar note, by removing hard-coded subroutine dependencies,
architectures like that of implementation 2B also tend to place an additional burden on
their top-level procedures to accurately compose these small independent functions into
a coherent pipeline. For example, since the refactored version of is_special is really
just an alias for or, it is arguably more likely for this version to be used
incorrectly than its predecessor, for example by passing in unrelated Booleans returned
by irrelevant inquiries.
Overall, it is difficult to provide a one-size-fits-all description of which subroutine
dependencies and nested architectures constitute truly upside-down code, much less a
perfect remedy for every such instance. In some cases, such as those involving I/O, the
scale tips heavily in favor of replacing subroutines to decrease coupling. In others,
such as the dependency between is_sequential and difference in implementation 2B, it
is near impossible, let alone reasonable, to do so. In general, however, I currently
believe that many developers could benefit greatly from reimagining their codebases with
an emphasis on removing subroutine dependencies. The tradeoffs between abstraction and
coupling must usually be considered on a case-by-case basis, but I hope that the
previous discussions can help motivate others that the exercise is often worthwhile. By
rethinking your architecture and its dependencies, not only might your code turn upside
down, you might just turn some frowns upside down too!
Postscript: two more descriptions
Yet again, you might think that this would be a good time to end, and you’d probably be right a second time! Even so, I somehow still have more to say about the topic of upside-down code. What follows are two additional descriptions of upside-down code: one conceptual and the other metaphorical. While I did not find a natural way of fitting them into the rest of the essay, I believe that they provide additional perspective on the topic and are therefore worth including.
The true meaning of “upside-down” code
Consider an abstract program consisting of four procedures, creatively named E, F,
G, and H; E serves as the entry point of the program, while F, G, and H
primarily serve as implementations of the (mathematical) functions , , and
respectively. Now, as we’ve seen before, an oft-preferred approach to organizing
a program like this is to abstract away the specifics of procedure H under G and of
G under F, especially when H and G perform operations considered to be
“low-level”.24 Below is a kind of
“sequence” diagram, depicting the flow
of control of such an architecture.
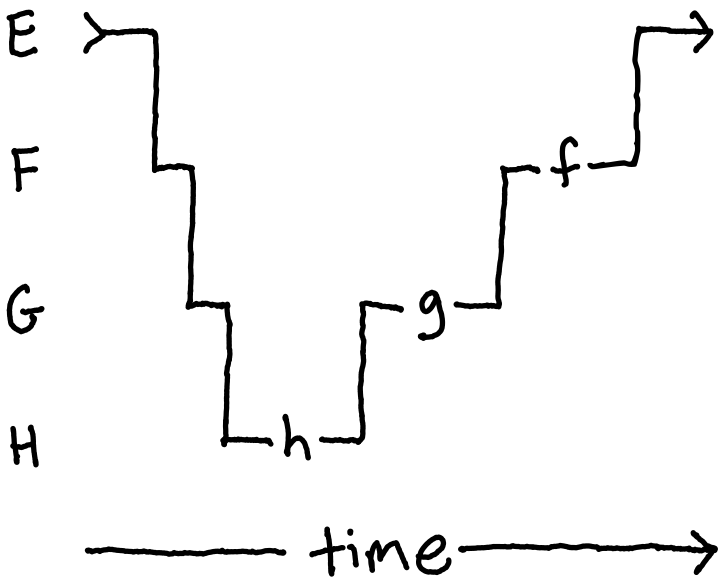
From this diagram, we can see that E calls F, which then calls G, which in turn
calls H. To reiterate, this design is usually justified by the fact that it is
beneficial to hide the details of G and H by burying them under increasingly deeper
levels of abstraction. We can also see in this diagram that this program is essentially
just an implementation of , the
composition of , , and
. With hope, this motivates us to recognize that subroutine invocation can be
thought of as just an implementation of function composition.
The problem with this approach, as I’ve previously described, is that it introduces a
significant amount of unnecessary coupling into the system. Not only do we have direct
dependencies of E on F, F on G, and G on H, but we also have many transitive
dependencies: F indirectly depends on H, while E similarly depends G and H.
I’ve repeatedly argued that this excessive coupling between subroutines is the
fundamental flaw of this kind of architecture.
Fortunately, subroutine dependencies are not the only way to implement function composition! There is yet another way, known in many contexts as the pipeline approach.25 In my opinion, this concept is best illustrated with yet another sequence diagram.
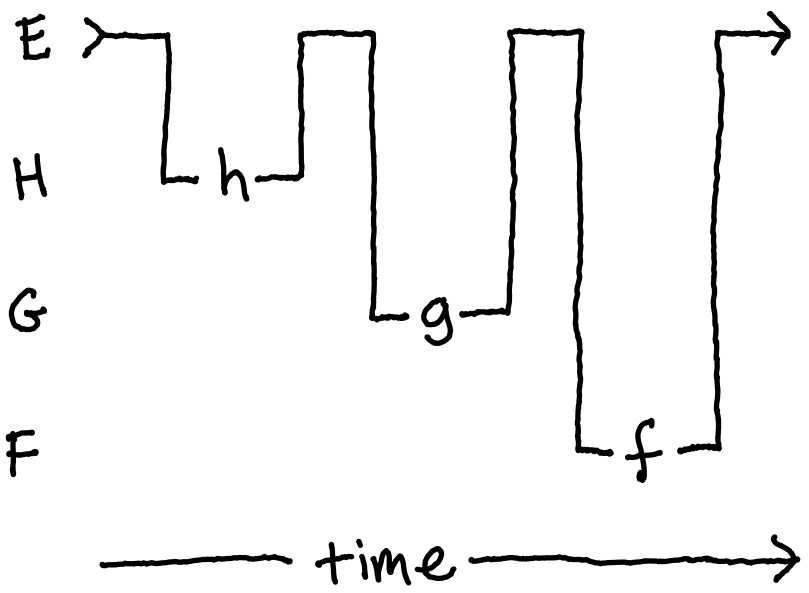
In this design, E now calls the implementations of , , and directly!
And, while potentially some abstraction has been lost, so too have the dependencies
between F and G, G and H, and even F and H – that’s half of all previous
dependencies! And this 50% reduction in coupling was yielded from a system that started
with just four levels of depth. More generally, the number of dependencies removed by
this process grows quadratically with the depth of the system being flattened.26
That’s a lot of decoupling!
It turns out we have seen these two architectures multiple times already, albeit in more concrete terms. In case the resemblance is still unclear, let us once again examine the dependency graph of these two implementations:
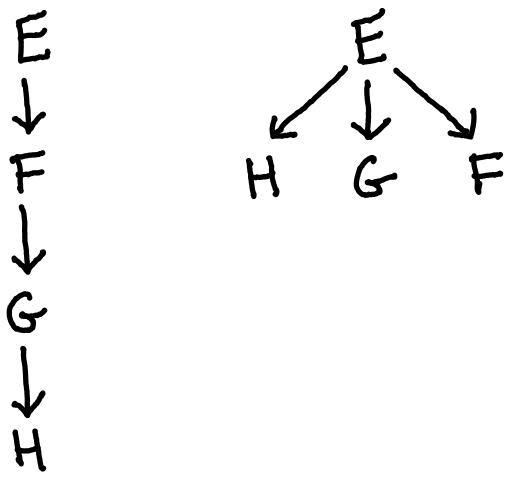
This is precisely the two architectures we have seen time and again in our previous examples. In the first graph, we see the familiar hierarchical structure of implementations 1A and 2A, while the second graph represents the refactored approach of programs 1B and 2B. Once again, we have taken a hierarchical structure of nested subroutines and flattened it into a pipeline of isolated components. This time, however, we see both the anti-pattern and its remedy presented entirely in abstract terms. With hope, this can help us truly recognize upside-down code for what it is, as well as what it takes to turn it right-side up.
Let’s now consider a final time what I mean when I say “turn your code upside down”.
Personally, I find that these new sequence diagrams are most evocative of this
expression. Notice how the flow of control progresses in the hierarchical model:
starting of course at the entry point, it first proceeds to F, then G then H.
Compare this with the pipeline model: the entry point calls H, followed by G, and
finally F. In other words, the pipeline model inverts the flow of control of the
hierarchical model. Moreover, when depicted in the sequence diagrams, this inversion
takes on a more visual interpretation from which we may conclude that, in some sense,
the pipeline model really is the hierarchical model turned upside down (note how the
vertical order of procedures in the two diagrams is essentially reversed). Hence, by
“turn your code upside down” I mean to say, refactor your codebase from a hierarchy to
a pipeline. This rather simple orientation shift underlies the many gains in
testability, reusability, simplicity, and even elegance that I have attested to so far.
The Parable of Silver Bell Labs
I’ve now likened the first, problematic architecture to a hierarchy, and the second, refactored architecture to a pipeline. From these analogies, a surprisingly appropriate metaphor emerges from the world of business administration. In particular, let us consider how these architectures relate to two particular organizational structures commonly found in business. In this metaphor, each procedure represents an employee, its contract represents her job responsibilities, and its body is her workflow for accomplishing tasks. Consequently, a procedure calling a subroutine amounts to one employee delegating some task to another. In business, the former employee is usually referred to as a “manager”, while the latter is referred to as a “(direct) report”.
When starting a business, the question inevitably arises of how to organize the corporate ladder. For our purposes, there are two noteworthy approaches to this problem, commonly known as the “hierarchical” approach and the “flat” approach to structuring a company. A hierarchical organization consists of many “middle managers”, managers who report to other managers. The job of a middle manager is usually to delegate work to each of their reports and then synthesize these pieces into a summary for their superior. This pattern of delegation and synthesis continues until everything has filtered up to the CEO. Contrast this with the “flat” organization, which consists of few or no middle managers. In other words, almost everyone reports to the “CEO” directly. I like to think of this model in the context of an assembly line. Each assembly line worker has a single, well-defined task that they can accomplish independently. Overseeing them all is a single administrator, who can inspect the production of each worker in isolation for quality control purposes.
What are the tradeoffs between these two organizational models? As a disclaimer, I have no experience with business administration, but even I recognize some rudimentary distinctions. In the hierarchical model, issues can arise from the very existence of delegation. If CEO Nick Claus of Silver Bell Labs needs a thousand toy cars built by the holidays, he might call upon his direct report Rudolph to assemble those cars. Rudolph, in turn, might delegate the production of tires to Buddy and the manufacturing of chassis to Hermey, from which he will assemble the whole. After inspecting the cars returned by Rudolph and noticing that many drift slightly to the left, Nick now has the unenviable task of determining who is responsible. Unfortunately for Nick, this is further complicated by the fact that, due to delegation, many low-level assembly processes are opaque. It is unclear whether he should hold Rudolph accountable for possibly bending the axles while attaching the tires, Buddy for potentially producing tires that put undue strain on the axles, or Hermey perhaps for producing brittle axles in the first place.
def nick():
return rudolph()
def rudolph():
tires = buddy()
chassis = hermey()
car = tires + chassis
return car
def buddy():
return tire * 4
def hermey():
return axle * 2 + frame
Compare this scenario to that of an assembly line. Now Nick delegates the task of toy car assembly to Rudolph, Buddy, and Hermey directly. Each employee will continue to perform their main tasks, but Nick will serve as an intermediary between each worker. Nick now inspects each tire produced by Buddy, each chassis constructed by Hermey, and each car assembled by Rudolph. Rudolph no longer has to interact with Hermey or Buddy directly because all the parts he receives will come from Nick. In addition, any defective parts that are produced will be caught by Nick before being forwarded to the next employee. It is therefore much easier for Nick to handle defective products and improve bad processes without halting production entirely. There are some downsides to this approach too, however. Nick now has more administrative work than before: he has to know who requires what parts and how to check whether axles are built to last. There is probably some threshold of scale or complexity after which point Nick may become overwhelmed with administrative work and will have no choice but to hire middle managers. But, until that day comes, Nick determines that it is worthwhile to organize his factory into a pipeline instead of a hierarchy.
def nick():
tires = buddy()
chassis = hermey()
return rudolph(tires, chassis)
def rudolph(tires, chassis):
car = tires + chassis
return car
def buddy():
return tire * 4
def hermey():
return axle * 2 + frame
With hope, the parallels between the tradeoffs at Silver Bell Labs and those in software
design are evident. The benefit provided by delegation via subroutines is abstraction,
while the downside is coupling. A deeply hierarchical architecture tends to benefit from
abstraction but at the expense of tight coupling. This is true regardless of whether I/O
is involved in the system, although the presence of I/O tends to make a preference for
abstraction over coupling untenable. In contrast to a hierarchical system, a flat system
designed as a pipeline benefits from loose coupling, and often only at the expense of a
little abstraction. The main procedure in each of implementations 1B and 2B indeed
bears more complexity, but the tradeoff is usually worthwhile because it endows all
other procedures with independence and reusability. All in all, if at any point you find
yourself contemplating how best to construct your own digital architecture, consider
following the footsteps of Nick Claus, and you may just end up with a very merry design!
Relevant Resources
- Brandon Rhodes’s PyOhio 2014 talk, “The Clean Architecture in Python”: this talk was the primary inspiration for this essay and is one of my favorite software design talks of all time.
- Brandon Rhodes’s PyWaw Summit 2015 talk, “Hoisting Your I/O”: I consider this to be a supplemental talk to “The Clean Architecture in Python” that provides more examples and adds more context.
- Gary Bernhardt’s PyCon 2013 talk, “Boundaries”16: An incredibly information-dense yet very understandable talk on a variety of ideas, including functional programming, unit testing, and even concurrency. In addition to “The Clean Architecture in Python”, this is also one of my favorite talks of all time.
-
Mark Seemann’s blog: In particular, the following essays are
relevant:
- “Functional architecture: a definition”: A great explanation of what makes an architecture “functional”.
-
“Functional architecture is Ports and Adapters”:
Seemann’s explanation of how Haskell uses its
IOtype to enforce a functional architecture. - “Impureim sandwich”: The particular subclass of “functional core, imperative shell” exhibited in implementations 2A and 2B.
- Edwin Jung’s PyCon 2019 talk, “Mocking and Patching Pitfalls”: A fantastic talk not just about mocking and patching, but also about the history of TDD and how it’s often executed incorrectly. This talk covers a lot of ground and is definitely worth a watch.
- “Learn You a Haskell for Great Good!” by Miran Lipovača: A fun, light, and free introduction to Haskell. This was the first resource I used when I started learning Haskell.
Definitions
In the following list, I attempt to pin down the definitions of several concepts that I use frequently throughout the essay. Please note that this list contains homonyms, so the intended sense of any particular word instance depends on its context.
- I/O: Short for “input and output”; any interaction between a program and the “outside world”. Since this affects the behavior of the program and/or changes the state of the outside world, it is a computational effect. Common I/O operations include printing to and reading from a terminal or file system, interacting with a network (like the Web), and checking the current time.
- [Mathematical] Function: A function in the mathematical sense. In particular, a mathematical function is an abstract concept and technically cannot exist inside a piece of software.
- Procedure: Any self-contained set of executable instructions intended to perform some computation. I mean this in the broadest sense of the word, so it includes all procedures, regardless of “purity”.
- [Computational/Pure] Function: A procedure that implements a mathematical function and does nothing else.
- Computational [side] effect: Any behavior of a procedure that renders it impure. Some notable computational effects include network and system I/O, mutable state, and randomness. A longer list of examples can be found here.
- [Impure] Procedure: A procedure that, in particular, happens to perform at least one computational side effect; that is, it is expressly not a pure function.
- Subroutine: A procedure that is invoked by some other procedure in the context of a program.
- [Subroutine] Dependency: A relationship between procedures in which one (the “caller”)
invokes another (the “callee”/”subroutine”) at runtime.
- [Direct]: A dependency that is encoded directly in the body of the calling procedure.
- [Indirect/Transitive]: A dependency implied transitively by the existence of two
other dependencies. For example, given three procedures,
A,B, andC, ifAdepends onBandBonC(directly or indirectly), thenAalso “indirectly” depends onC.
-
The following groundwork code is provided for anyone interested in actually running this program:
""" The "holiday countdown" program: prints the number of days until the soonest US holiday. """ from dataclasses import dataclass from datetime import date from typing import Collection, List, TypedDict import requests # A minimal model of the JSON schema returned by the holiday API HolidayDict = TypedDict("HolidayDict", {"name": str, "date": str}) @dataclass class Holiday: name: str date: date # Insert implementation 1A or 1B here if __name__ == "__main__": main()Please note also that this program depends on the Requests library. Hence that library will need to be installed to run the program exactly as provided. ↩ ↩2
-
This essay refers to the concept of I/O a lot. For a more precise definition of this term, please consult the list of associated definitions. ↩
-
2024-07-08 Note: When this essay was originally published, the provided code examples made use of version 1 of the holiday API. Even at that time, newer versions of that API existed. However, I intentionally ignored them and provided the following rationale for that decision:
A careful reader might notice that newer versions of the holiday API than that being used (version 1) indeed already exist. Moreover, these newer versions even add functionality that would further simplify any implementation of this program. In light of this, my choice of API version for these examples might be surprising. I assure, however, that the decision to use an outdated API version was intentional; in particular, it was pedagogical. For the sake of illustrating the larger argument, some of the complexity of the problem must reside in the implementations themselves, as the management of this complexity is the focus of the ensuing discussion. Choosing a later API version would only serve to circumvent this prerequisite complexity so I opted to pretend as though the program was implemented in absence of these improved API capabilities. Moreover, this hypothetical premise illustrates the very point I am trying to make: many details of I/O interaction are arbitrary and subject to change; you never know when an upstream team might release a new API version, for better or for worse.
As of writing this update, version 1 of the holiday API has reached end-of-life (that is, it is no longer available) and version 2 will follow soon. Because of this, I have since updated the code to use version 3 of the API. This has no effect on the essay except for the originally noted fact that this new API version provides additional functionality that could be used to simplify some implementation details, albeit at the expense of pedagogical value. Hence, I will continue to ignore these new API features. ↩
-
Even though complexity is a subjective concept, one objective attempt at measuring this quality is that of cyclomatic complexity. According to this particular measure, every procedure in this program scores a 1, the lowest (i.e. best) possible score. Hence it is indeed quite reasonable to call this program simple. ↩
-
This architecture is sometimes called the “traditional layers pattern” or “top-down design”. Notice the visual similarity between the dependency graph of implementation 1A, this traditional layers diagram provided on Wikipedia, and this diagram for top-down design from this fantastic 2019 PyCon talk by Edwin Jung. ↩
-
In his talk, Brandon Rhodes points out that dependency injection and
mock.patchcan technically circumvent issues like this, but not without their own drawbacks. In short, mocking and patching, even when used with dependency injection, are often inelegant workarounds for badly designed code, which is why I won’t consider them further. For a more in-depth critique of these methods, see Rhodes’s own talk, Gary Bernhardt’s PyCon 2013 talk “Boundaries”16, and Edwin Jung’s PyCon 2019 talk “Mocking and Patching Pitfalls”. ↩ -
Rhodes, Brandon. “The Clean Architecture in Python”. (5:32). PyOhio, 2014. ↩
-
In this fantastic PyCon 2019 talk, Edwin Jung refers to this anti-pattern as “bootleg TDD”, describes how it reinforces this kind of design process (which he calls “procedural decomposition”), and how this results in the architecture exhibited by implementation 1A (which he calls “top-down design”). ↩
-
Rhodes, Brandon. “The Clean Architecture in Python”. (1:44). PyOhio, 2014. ↩
-
In some circumstances, decoupling I/O even has a fourth advantage, one which is arguably even more important than the other three: correctness. In this essay, I have attempted to limit the discussion of I/O solely to network I/O, which in the examples provided does not affect correctness. However, there is another source of I/O in these implementations that the careful reader might have noticed, and that is system I/O. In particular, the current system time is requested at least once in each implementation of the holiday countdown program, in order to determine the current date. Accessing system time incautiously tends to introduce subtle bugs into a program, and decoupling I/O leads to designs that avoid these pitfalls in the first place.
Accessing system time is a standard computational side effect, since, by definition, the information returned depends on when it was requested. In theory, system I/O is therefore no different from network I/O. In practice, however, system I/O tends to have slightly different caveats. First, requesting the current system time is far less time-consuming and error-prone than interacting with a network. Moreover, it tends to be a lot simpler to use. Interacting with a web API often involves importing an HTTP library like Requests, defining models for request and response schemas, and handling network errors. Requesting the current system time, on the other hand, is as simple as calling a single built-in procedure:
date.today()(ordatetime.now()). Unfortunately, this simplicity is a double-edged sword, and can even become a footgun for the incautious programmer.It turns out that implementation 1A contains a very small bug, which once again results from the fact that I/O is buried and distributed throughout the program. Notice that
date.today()is invoked bydays_until, which in turn is called in several places throughout the codebase. In particular,fetch_next_holidayinvokesdays_untilindirectly when determining whether each holiday is indeed “upcoming”, andmaininvokesdays_untildirectly to determine the number of days until the nearest holiday. Importantly, time elapses between these invocations, which can cause unexpected behavior.Let’s consider the ramifications of this behavior. Consider a scenario in which an unassuming user runs this program right before the stroke of midnight on Christmas Day. If run early enough,
fetch_next_holidaywill determine that the nearest upcoming holiday is the current day, Christmas. However, if the clock strikes midnight immediately after this holiday is returned tomain, the subsequent call todays_untilwill show that Christmas has already passed, and the resulting output of the program will be “Only -1 more day(s) until Christmas Day!”, much to the surprise of the user. Personally, I consider this behavior to be a bug, and I know from experience that issues like this tend to show up in real codebases that depend on the time.In contrast, implementation 1B cannot exhibit this behavior. The current time is only retrieved once, after which point it is shared throughout the system. All components, therefore, agree about what day it is throughout the runtime of the program, which means
find_next_holidaywill never pick a day thatmaindetermines to have already passed. This consistency is yet another consequence of hoisting and centralizing I/O at the top of the system. When a single source of truth trickles down from the top, it tends to improve consistency, and therefore correctness, throughout the codebase. ↩ -
For the precise meaning of “pure function”, please consult the list of associated definitions. ↩
-
Rhodes, Brandon. “Hoisting Your I/O”. (17:37). PyWaw Summit, 2015. ↩
-
Rhodes, Brandon. “The Clean Architecture in Python”. (39:52). PyOhio, 2014. ↩
-
Bernhardt, Gary. “Boundaries”. (31:00). SCNA, 2012. ↩
-
Rhodes, Brandon. “The Clean Architecture in Python”. (25:58). PyOhio, 2014. ↩
-
The version of “Boundaries” linked above is from PyCon 2015, and so all of its example code is conveniently written in Python. There are also two other versions of this talk (written in Ruby), one from SCNA 2012 and one from RubyConf 2012. ↩ ↩2 ↩3
-
Lipovača, Miran. “Input and Output”. Learn You a Haskell for Great Good!: A Beginner’s Guide, 2011. ↩
-
Seemann, Mark. “Functional architecture: a definition”. Ploeh Blog, 2018. ↩ ↩2 ↩3
-
Seemann, Mark. “Functional architecture is Ports and Adapters”. Ploeh Blog, 2016. ↩
-
To say that “the others may have overlooked” what I discuss in the remainder of the essay is admittedly a bit of an exaggeration. There is good reason to believe, for example, that both Brandon Rhodes and Gary Bernhardt are indeed aware of the central role that the subroutine plays in upside-down code. In his 2014 talk, Rhodes laments that “programmers have been spontaneously using subroutines backwards”27 and argues that “data and transforms are easier to understand and maintain than coupled procedures”28. Bernhardt, for his part, explains that a defining characteristic of a true “functional core” is that it has “very few dependencies and hopefully none”29. Taken charitably, these remarks imply that both Rhodes and Bernhardt understand that subroutine dependencies play a critical role in upside-down code. Even so, I believe that Rhodes and Bernhardt at the very least fail to place sufficient emphasis on this revelation, as they appear to gloss over it in but a few sentences. Hence, the purpose of this essay is at very least to redistribute this emphasis accordingly. ↩
-
The following groundwork code is provided for anyone interested in actually running this program:
""" The "special dates" program: prints whether the current date, when written in US date notation, looks "special". """ from datetime import date from itertools import pairwise from typing import Collection, Hashable, List, Sequence, Tuple # Insert implementation 2A or 2B here if __name__ == "__main__": main() -
Arguably, this is really two distinct tests unnecessarily combined under a single procedure. In a real codebase, I would separate them (or even better, parameterize the procedure) but, for the sake of brevity, I have left them combined. ↩
-
The skeptical reader might protest that, while it is true that this version of
test_create_msgisn’t required to change in response to the updated software requirements, it ideally still should be updated to remain compliant with the new behavior ofis_special. After all,ORDINARY_DATE(12/12/12) is now considered “special”, socreate_msg(ORDINARY_DATE, False)should be considered an invalid scenario (not to mention, the nameORDINARY_DATEis no longer appropriate). Furthermore, if all this is to be believed, then we haven’t actually gained anything from this approach after all, since we still have to make a comparable code change to that in the other scenario.I strongly disagree with this perspective, however. As I will argue further later, modifying
create_msgto remove its subroutine dependencies doesn’t just isolate it in a practical sense, but also in a philosophical sense. More concretely, the version ofcreate_msgin implementation 1B is a generalization of its counterpart in implementation 1A and not merely an interchangeable implementation of the same underlying idea. For this reason, even if the behavior ofis_specialdoes evolve, this does not count as a reason to update the test ofcreate_msg, because the scenarios described in that test genuinely remain valid under this new definition ofcreate_msg. ↩ -
Written in Python, this implementation would look something like this:
def E(): # retrieve a = input d = F(a) # respond with output = d def F(a): c = G(a) # compute d = f(c) return d def G(a): b = H(a) # compute c = g(b) return c def H(a): # compute b = h(a) return bCompare this implementation with that of the flat/pipeline architecture presented in footnote 25. ↩
-
Written in Python, this implementation would look something like this:
def E(): # retrieve a = input b = H(a) c = G(b) d = F(c) # respond with output = d def H(a): # compute b = h(a) return b def G(b): # compute c = g(b) return c def F(c): # compute d = f(c) return dCompare this implementation with that of the hierarchical architecture presented in footnote 24. ↩
-
For the mathematically inclined, say we have a system composed of procedures arranged conceptually into a list, and each previous procedure in this list directly depends on the next. Assume also that it is possible to refactor this system into a “flat” pipeline, in which only one procedure, serving as the entry point, directly depends on all the others, but which otherwise lacks any other dependencies.
Clearly, the latter (hereafter “pipeline”) architecture has dependencies (all of them direct), one for each procedure aside from the entry point. It is also not too difficult to show inductively that there are dependencies (most of them indirect) in the former (hereafter “hierarchical”) architecture. From here, it follows that refactoring from the hierarchical to pipeline architecture removes dependencies. In other words, the amount of unnecessary coupling in a perfectly hierarchical architecture increases by the square of the depth of the hierarchy! ↩
-
Rhodes, Brandon. “The Clean Architecture in Python”. (2:16). PyOhio, 2014. ↩
-
Rhodes, Brandon. “The Clean Architecture in Python”. (41:35). PyOhio, 2014. ↩